Classification is a fundamental machine learning technique used to predict the group membership of data instances based on input features. The Iris dataset, a well-known benchmark in machine learning, presents a classification challenge involving three species of the Iris plant based on sepal and petal measurements. This paper explores the application of Support Vector Machines (SVM) combined with Principal Component Analysis (PCA) for dimensionality reduction to enhance classification accuracy and interpretability. Performance metrics, including precision, recall, F1 score, and confusion matrices, are analyzed to evaluate model effectiveness. The study demonstrates that while SVM achieves high classification accuracy, Decision Trees provide greater interpretability, which is valuable for practical applications in biological classification.
Introduction
Bioinformatics is an emerging and rapidly evolving field focused on extracting meaningful insights from biological data using computational techniques. Fundamental challenges in bioinformatics, such as protein structure prediction, sequence alignment, and phylogenetic inference, are often computationally complex and classified as NP-hard problems. Machine learning (ML) methods, including Artificial Neural Networks (ANN), Fuzzy Logic, Genetic Algorithms, and Support Vector Machines (SVM), have shown promise in addressing these challenges.
This study focuses on classifying Iris species using measurements of sepal length, sepal width, petal length, and petal width. The Iris dataset, introduced by R.A. Fisher in 1936, has become a standard benchmark for classification models. The goal is to evaluate the effectiveness of SVM for classification and explore the impact of dimensionality reduction using PCA on model performance. Decision Tree models are also assessed for comparison, balancing accuracy with interpretability.
Data
The Iris dataset, obtained from the UCI Machine Learning Repository, consists of 150 instances representing three species of Iris plants:
Iris Setosa
Iris Versicolor
Iris Virginica
Each species is represented by 50 samples. The dataset includes four numeric attributes:
Sepal length (cm)
Sepal width (cm)
Petal length (cm)
Petal width (cm)
Code
data = get_data("iris")decoder = ['setosa', 'versicolor', 'virginica']
Iris Measures
sepal_length
sepal_width
petal_length
petal_width
species
0
5.1
3.5
1.4
0.2
Iris-setosa
1
4.9
3.0
1.4
0.2
Iris-setosa
2
4.7
3.2
1.3
0.2
Iris-setosa
3
4.6
3.1
1.5
0.2
Iris-setosa
4
5.0
3.6
1.4
0.2
Iris-setosa
The fifth attribute is the class label indicating the species. The dataset is complete, with no missing values or inconsistencies reported. While the Setosa species is separable from the other two species, Versicolor and Virginica exhibit significant overlap, making classification the challenge of the study. A copy of the exploratory data report can be found here EDA Report
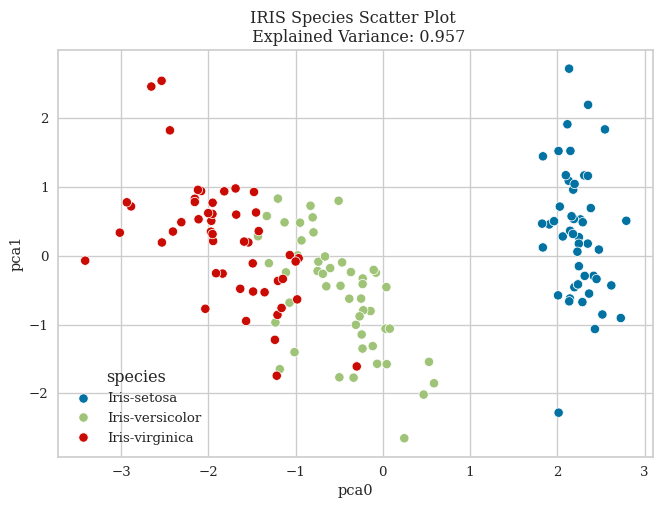
Principal Component Analysis (PCA) is a widely used dimensionality reduction technique that can project data onto a lower-dimensional subspace while retaining the maximum variance. PCA helps reduce the computational complexity of the classification task, but more importantly in this instance, improves visualization.
In this study, PCA reduces the four-dimensional Iris data into two principal components:
First Principal Component: Accounts for the highest variance in the data.
Second Principal Component: Captures the next highest variance.
By plotting the data along these two principal components, a clear separation between the Setosa species and the other two species becomes visible. However, Versicolor and Virginica still exhibit considerable overlap.
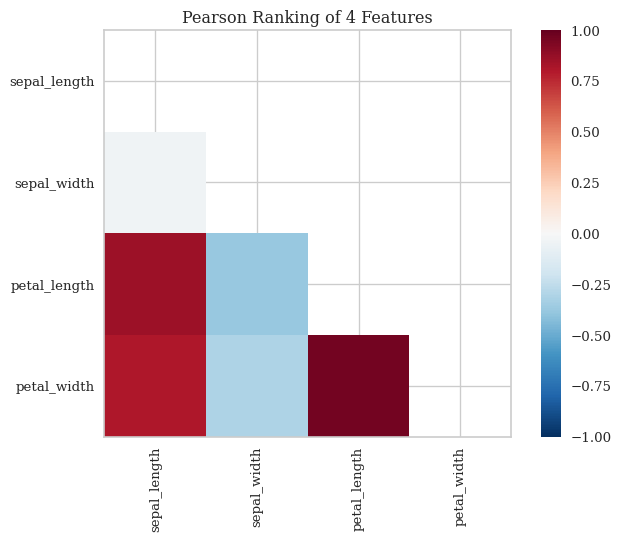
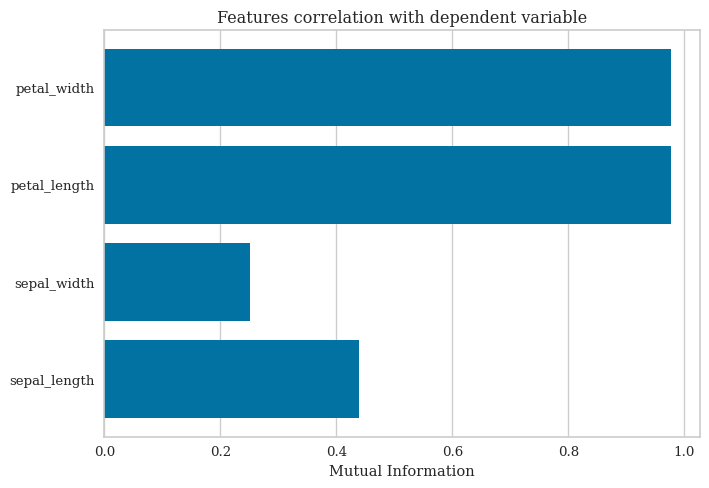
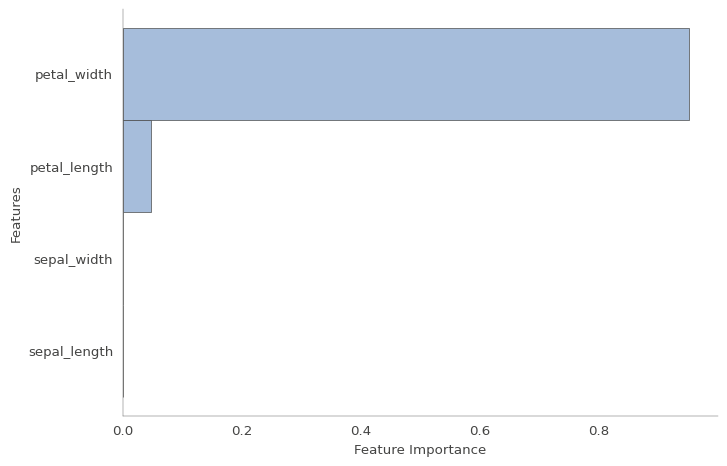
While PCA is great for dimensionality reduction and visualization, we do lose some interpretability in how the scientific measurements are correlated to the target species. For this, we look at feature rank and feature importance charts to determine the measurements most affecting the separation between classes.
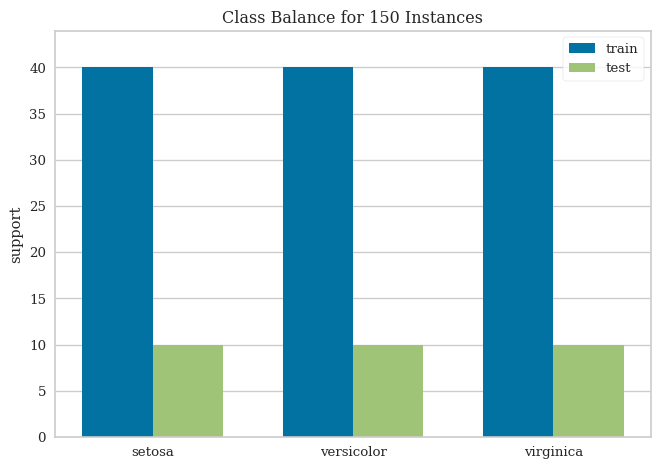
Standard practice is to perform train test split on the transformed data to evaluate the model performance. We will use the convention that splits the data in 80% training/validation and 20% test set. Because the sample size is relatively small, we will use cross validation to prevent overfitting. The advantages of this technique are the ability to limit overfitting on a relatively small dataset.
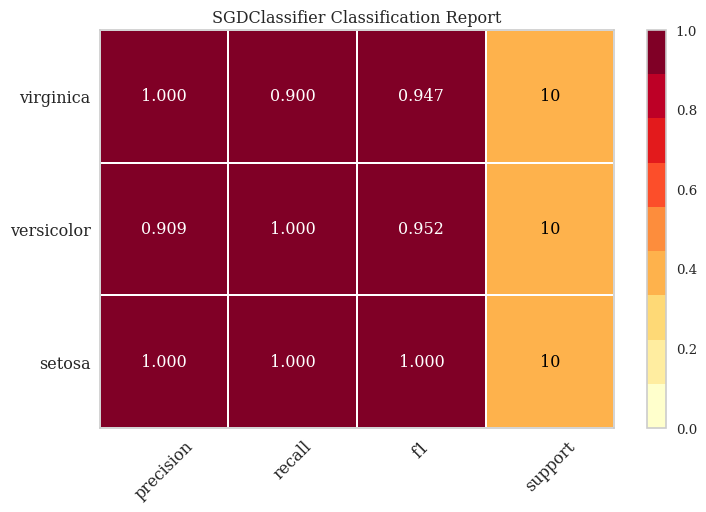
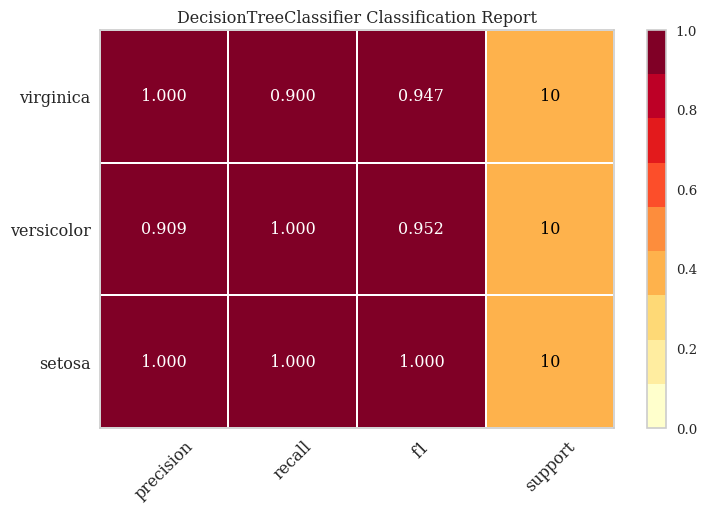
The models were evaluated using an 80/20 train-test split with five-fold cross-validation to mitigate overfitting. Evaluation metrics included:
Precision – The proportion of correct positive predictions.
Recall – The proportion of actual positives correctly identified.
F1 Score – The harmonic mean of precision and recall, providing a balanced measure of model accuracy.
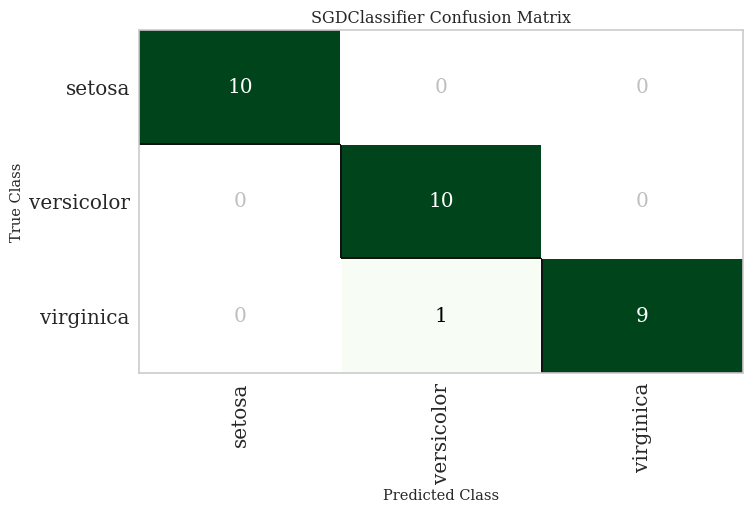
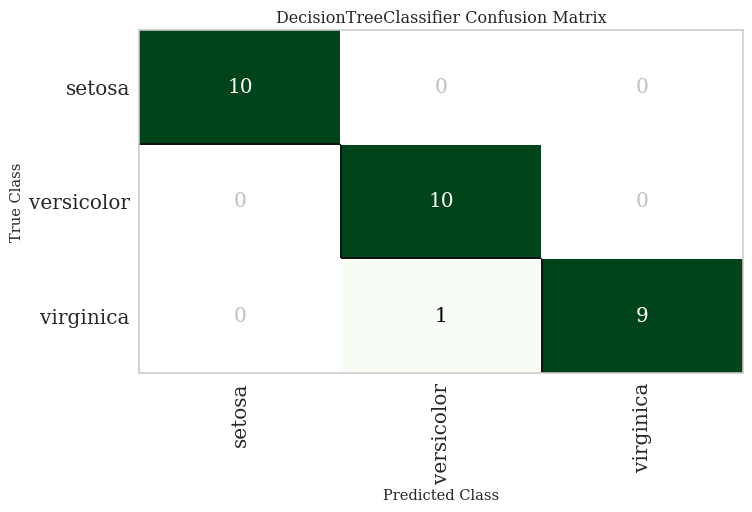
Confusion Matrix - Illustrates misclassification patterns across species.
Classification by Support Vector Machine
Support Vector Machines (SVM) are effective for high-dimensional classification problems. SVM constructs a hyperplane in a multi-dimensional space that maximally separates the classes. In cases where the data is not linearly separable, SVM employs a kernel trick to map the data into a higher-dimensional space where linear separation becomes possible.
Code
svm_model = create_model("svm", tol=1e-3, alpha=.0012, verbose=False) # parameters can be found with tune_modelpull()
Cross Validation Results
Accuracy
AUC
Recall
Prec.
F1
Kappa
MCC
Fold
0
0.7500
0.0
0.7500
0.7556
0.7460
0.6250
0.6316
1
0.9167
0.0
0.9167
0.9333
0.9153
0.8750
0.8843
2
0.9167
0.0
0.9167
0.9333
0.9153
0.8750
0.8843
3
0.9167
0.0
0.9167
0.9333
0.9153
0.8750
0.8843
4
1.0000
0.0
1.0000
1.0000
1.0000
1.0000
1.0000
5
0.8333
0.0
0.8333
0.8333
0.8333
0.7500
0.7500
6
1.0000
0.0
1.0000
1.0000
1.0000
1.0000
1.0000
7
1.0000
0.0
1.0000
1.0000
1.0000
1.0000
1.0000
8
0.9167
0.0
0.9167
0.9333
0.9153
0.8750
0.8843
9
0.8333
0.0
0.8333
0.8889
0.8222
0.7500
0.7833
Mean
0.9083
0.0
0.9083
0.9211
0.9063
0.8625
0.8702
Std
0.0786
0.0
0.0786
0.0744
0.0805
0.1179
0.1141
Comparison to Decision Tree
A Decision Tree classifier was used as a benchmark to compare with the SVM model. Decision Trees provide an interpretable model by recursively splitting the data based on the most informative features. The tree structure allows for straightforward interpretation of how classifications are made.
The Decision Tree model achieved comparable performance, almost identical to the Support Vector Machine. This is a common phenomenon in machine learning applications and often greatly ignored by auto=ml packages. Decision Trees, provide a more transparent decision-making process, which is valuable for field applications where understanding the classification process is essential.
A simple decision tree can be printed out as a flowchart or a series of branching yes/no questions, making it easy to use in field work where quick decisions are necessary. Each node in the tree represents a question based on a specific feature, such as “Is petal length greater than 2.5 cm?” The branches lead to subsequent questions or to a classification decision, such as identifying the plant as Setosa or Versicolor. This format allows field researchers to visually trace the decision path step-by-step, even without access to computational tools. The straightforward structure of a decision tree makes it easy to understand and follow, enabling non-experts to accurately classify samples based on observable characteristics. The transparency and simplicity of the printed decision tree make it particularly valuable for practical applications in biological fieldwork.
Code
# Build a model on the final data for deployment.env_prod = setup(data, target="species", train_size =.8, session_id = RANDOM_STATE, verbose =False) # trees don't need normalizationfinal_tree = finalize_model(tree_model)message = save_model(final_tree, "models/production-model", verbose =False)
In-case displaying the entire tree is not desirable especially in regulatory environments, we can instead display the list of features and their importance related to the decision.
Misclassification between Versicolor and Virginica reflects the biological similarities in their sepal and petal measurements. Future research could explore additional botanical features or incorporate other ML techniques, such as ensemble methods or deep learning, to improve discrimination between these species.
SVM remains a powerful classification tool for complex, high-dimensional datasets. However, the increased interpretability of Decision Trees suggests that they may be more suitable for practical, real-world applications in biological research.
Conclusion
This study demonstrates the effectiveness of SVM in classifying Iris species based on sepal and petal measurements. PCA successfully reduced the data dimensionality, improving visualization. SVM achieves high accuracy, however, the interpretability of Decision Trees makes them a valuable alternative for practical applications where model transparency is critical.
Future Work
Future work could explore:
Incorporating additional morphological features to improve classification between Versicolor and Virginica.
Testing ensemble methods such as Random Forest or Gradient Boosted Trees for enhanced accuracy.
---date: '2024-03-08'title: "Example Paper"categories: [Paper, Python, Dataviz]image: "/assets/Iris_pca.png"title-block-banner: falseformat: html: toc: true code-fold: true code-tools: true link-external-icon: true link-external-newwindow: true---```{python}#| output: falseimport iofrom sklearn import get_configfrom config import save_systemfrom encryption import RandomStateimport tomlifrom contextlib import redirect_stdout# remove stupid advertf = io.StringIO()with redirect_stdout(f):import ydata_profiling as ydfrom pycaret.datasets import get_datafrom pycaret.classification.functional import setup, get_config, compare_models, create_model, pull, finalize_model, save_model, plot_modelimport seaborn as snsimport matplotlib.pyplot as pltplt.rcParams['font.family'] ='DeJavu Serif'plt.rcParams['font.serif'] = ['Times New Roman']from yellowbrick.features import rank2dimport yellowbrick as ybimport dtreeviz``````{python}save_system()withopen("../../pyproject.toml", mode="rb") as fp: config = tomli.load(fp)PROJECT_NAME = config["tool"]["poetry"]["name"]RANDOM_STATE = RandomState(PROJECT_NAME).state```# Classifying Irises by Field Measurements*Classification is a fundamental machine learning technique used to predict the group membership of data instances based on input features. The Iris dataset, a well-known benchmark in machine learning, presents a classification challenge involving three species of the Iris plant based on sepal and petal measurements. This paper explores the application of Support Vector Machines (SVM) combined with Principal Component Analysis (PCA) for dimensionality reduction to enhance classification accuracy and interpretability. Performance metrics, including precision, recall, F1 score, and confusion matrices, are analyzed to evaluate model effectiveness. The study demonstrates that while SVM achieves high classification accuracy, Decision Trees provide greater interpretability, which is valuable for practical applications in biological classification.*## IntroductionBioinformatics is an emerging and rapidly evolving field focused on extracting meaningful insights from biological data using computational techniques. Fundamental challenges in bioinformatics, such as protein structure prediction, sequence alignment, and phylogenetic inference, are often computationally complex and classified as NP-hard problems. Machine learning (ML) methods, including Artificial Neural Networks (ANN), Fuzzy Logic, Genetic Algorithms, and Support Vector Machines (SVM), have shown promise in addressing these challenges.This study focuses on classifying Iris species using measurements of sepal length, sepal width, petal length, and petal width. The Iris dataset, introduced by R.A. Fisher in 1936, has become a standard benchmark for classification models. The goal is to evaluate the effectiveness of SVM for classification and explore the impact of dimensionality reduction using PCA on model performance. Decision Tree models are also assessed for comparison, balancing accuracy with interpretability.## DataThe Iris dataset, obtained from the UCI Machine Learning Repository, consists of 150 instances representing three species of Iris plants: - Iris Setosa - Iris Versicolor - Iris VirginicaEach species is represented by 50 samples. The dataset includes four numeric attributes: - Sepal length (cm) - Sepal width (cm) - Petal length (cm) - Petal width (cm)```{python}#| tbl-cap: Iris Measuresdata = get_data("iris")decoder = ['setosa', 'versicolor', 'virginica']```The fifth attribute is the class label indicating the species. The dataset is complete, with no missing values or inconsistencies reported. While the Setosa species is separable from the other two species, Versicolor and Virginica exhibit significant overlap, making classification the challenge of the study.A copy of the exploratory data report can be found here [EDA Report](../../assets/Iris_EDA.html)```{python}report = data.profile_report(progress_bar=False, title="Iris EDA Report")report.to_file("../../assets/Iris_EDA.html", silent =True)```## MethodsPrincipal Component Analysis (PCA) is a widely used dimensionality reduction technique that can project data onto a lower-dimensional subspace while retaining the maximum variance. PCA helps reduce the computational complexity of the classification task, but more importantly in this instance, improves visualization.In this study, PCA reduces the four-dimensional Iris data into two principal components: - First Principal Component: Accounts for the highest variance in the data. - Second Principal Component: Captures the next highest variance.```{python}env_pca = setup(data, target="species", train_size =.8, session_id = RANDOM_STATE, pca=True, pca_components =2, verbose =False, normalize =True)``````{python}#| tbl-cap: Reduced Dimension Measurementsenv_pca.X_transformed.head()```By plotting the data along these two principal components, a clear separation between the Setosa species and the other two species becomes visible. However, Versicolor and Virginica still exhibit considerable overlap.```{python}pca = env_pca.pipeline.named_steps["pca"].transformerplt.figure()sns.scatterplot(env_pca.X_transformed, x="pca0", y="pca1", hue=data["species"]).set(title="IRIS Species Scatter Plot \n Explained Variance: %.3f"% pca.explained_variance_ratio_.sum())```### Feature ImportanceWhile PCA is great for dimensionality reduction and visualization, we do lose some interpretability in how the scientific measurements are correlated to the target species. For this, we look at feature rank and feature importance charts to determine the measurements most affecting the separation between classes.```{python}env_norm = setup(data, target="species", train_size =.8, session_id = RANDOM_STATE, verbose =False, normalize=True)``````{python}#| layout-ncol: 2#| fig-cap: #| - "Pairwise Feature Correlation"#| - "Target Correlation"fig = rank2d(get_config("X_train"), get_config("y_train"))fig = yb.target.feature_correlation.feature_correlation(env_norm.X_train, env_norm.y_train, method='mutual_info-classification')```<br>Standard practice is to perform train test split on the transformed data to evaluate the model performance.We will use the convention that splits the data in 80% training/validation and 20% test set.Because the sample size is relatively small, we will use cross validation to prevent overfitting.The advantages of this technique are the ability to limit overfitting on a relatively small dataset.```{python}fig = yb.target.class_balance(env_norm.y_train, env_norm.y_test, labels = decoder)```## AnalysisThe models were evaluated using an 80/20 train-test split with five-fold cross-validation to mitigate overfitting. Evaluation metrics included: - Precision – The proportion of correct positive predictions. - Recall – The proportion of actual positives correctly identified. - F1 Score – The harmonic mean of precision and recall, providing a balanced measure of model accuracy. - Confusion Matrix - Illustrates misclassification patterns across species.### Classification by Support Vector Machine Support Vector Machines (SVM) are effective for high-dimensional classification problems. SVM constructs a hyperplane in a multi-dimensional space that maximally separates the classes. In cases where the data is not linearly separable, SVM employs a kernel trick to map the data into a higher-dimensional space where linear separation becomes possible. ```{python}#| tbl-cap: Cross Validation Resultssvm_model = create_model("svm", tol=1e-3, alpha=.0012, verbose=False) # parameters can be found with tune_modelpull()```### Comparison to Decision TreeA Decision Tree classifier was used as a benchmark to compare with the SVM model. Decision Trees provide an interpretable model by recursively splitting the data based on the most informative features. The tree structure allows for straightforward interpretation of how classifications are made.```{python}tree_model = create_model("dt", max_depth=3, verbose =False)winning_model = compare_models(include=[svm_model, tree_model], verbose =False)pull()```::: {#fig-metrics layout-ncol=2}```{python}fig = plot_model(svm_model, plot ="confusion_matrix", plot_kwargs = {"classes": decoder})``````{python}fig = plot_model(tree_model, plot ="confusion_matrix", plot_kwargs = {"classes": decoder})``````{python}fig = plot_model(svm_model, plot ="class_report", plot_kwargs = {"classes": decoder})``````{python}fig = plot_model(tree_model, plot ="class_report", plot_kwargs = {"classes": decoder})```:::The Decision Tree model achieved comparable performance, almost identical to the Support Vector Machine. This is a common phenomenon in machine learning applications and often greatly ignored by auto=ml packages. Decision Trees, provide a more transparent decision-making process, which is valuable for field applications where understanding the classification process is essential.```{python}message = save_model(svm_model, "models/svm-model", verbose =False)message = save_model(tree_model, "models/tree-model", verbose =False)```### Model InterpretabilityA simple decision tree can be printed out as a flowchart or a series of branching yes/no questions, making it easy to use in field work where quick decisions are necessary. Each node in the tree represents a question based on a specific feature, such as "Is petal length greater than 2.5 cm?" The branches lead to subsequent questions or to a classification decision, such as identifying the plant as Setosa or Versicolor. This format allows field researchers to visually trace the decision path step-by-step, even without access to computational tools. The straightforward structure of a decision tree makes it easy to understand and follow, enabling non-experts to accurately classify samples based on observable characteristics. The transparency and simplicity of the printed decision tree make it particularly valuable for practical applications in biological fieldwork.```{python}# Build a model on the final data for deployment.env_prod = setup(data, target="species", train_size =.8, session_id = RANDOM_STATE, verbose =False) # trees don't need normalizationfinal_tree = finalize_model(tree_model)message = save_model(final_tree, "models/production-model", verbose =False)``````{python}# Visualize predictionssample = env_prod.X_transformed.iloc[120] final_tree_model = final_tree.named_steps['actual_estimator']viz_model = dtreeviz.model(final_tree_model, X_train=env_prod.X_transformed, y_train = env_prod.y_transformed, feature_names =list(env_prod.X_transformed), target_name ="species name", class_names = decoder)viz_model.view(x = sample, fontname="DejaVu Sans")```In-case displaying the entire tree is not desirable especially in regulatory environments, we can instead display the list of features and their importance related to the decision. ```{python}viz_model.instance_feature_importance(sample, fontname="DejaVu Sans")```## Conclusion### DiscussionMisclassification between Versicolor and Virginica reflects the biological similarities in their sepal and petal measurements. Future research could explore additional botanical features or incorporate other ML techniques, such as ensemble methods or deep learning, to improve discrimination between these species.SVM remains a powerful classification tool for complex, high-dimensional datasets. However, the increased interpretability of Decision Trees suggests that they may be more suitable for practical, real-world applications in biological research.### ConclusionThis study demonstrates the effectiveness of SVM in classifying Iris species based on sepal and petal measurements. PCA successfully reduced the data dimensionality, improving visualization. SVM achieves high accuracy, however, the interpretability of Decision Trees makes them a valuable alternative for practical applications where model transparency is critical.### Future WorkFuture work could explore: - Incorporating additional morphological features to improve classification between Versicolor and Virginica. - Testing ensemble methods such as Random Forest or Gradient Boosted Trees for enhanced accuracy.## AppendixThe entire website, including this example project is located at [https://github.com/joshuacharleshyatt/personal](https://github.com/joshuacharleshyatt/personal)